


.png)
Introduction
In this tutorial you'll use SenseML to extract structured data from a certificate of liability insurance PDF.
Why extract data from an insurance certificate?
Certificates of liability insurance PDFs are everywhere — they’re generated almost any time companies want to work together in the physical world. Companies then have a burden of proving compliance. For example, a construction firm might have to prove minimum coverage requirements for their subcontractors. Often, this means an actual human has to open a PDF, read it, and verify compliance.
But what if you could skip the human step and extract the compliance information automatically from the PDF? Enter Sensible.
What's SenseML?
SenseML is Sensible’s JSON-formatted query language for extracting information from PDFs. SenseML is powered by a mix of techniques, including machine learning, heuristics, and rules. If you can write basic SQL queries, you can write SenseML queries!
What we'll cover
At Sensible, we provide our customers with customizable SenseML queries to extract data from insurance certificates and other documents. In this post, you’ll learn to write your own "configs" (SenseML queries) for your own documents, as well as modify any configs we provide you with.
Prerequisites
- You’ll need an account for Sensible. Or, read along for a rough idea of how things work.
- You’ll need to download an example insurance certificate PDF.
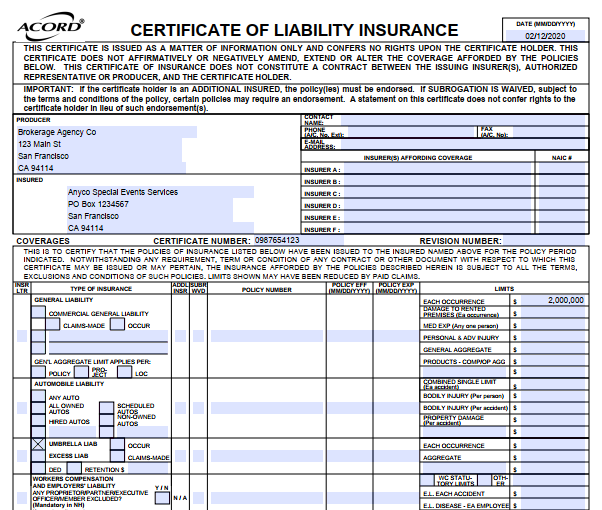
The example insurance certificate is sparsely populated with some placeholder data:
Create a document type
1. Login at app.sensible.so using your API key.
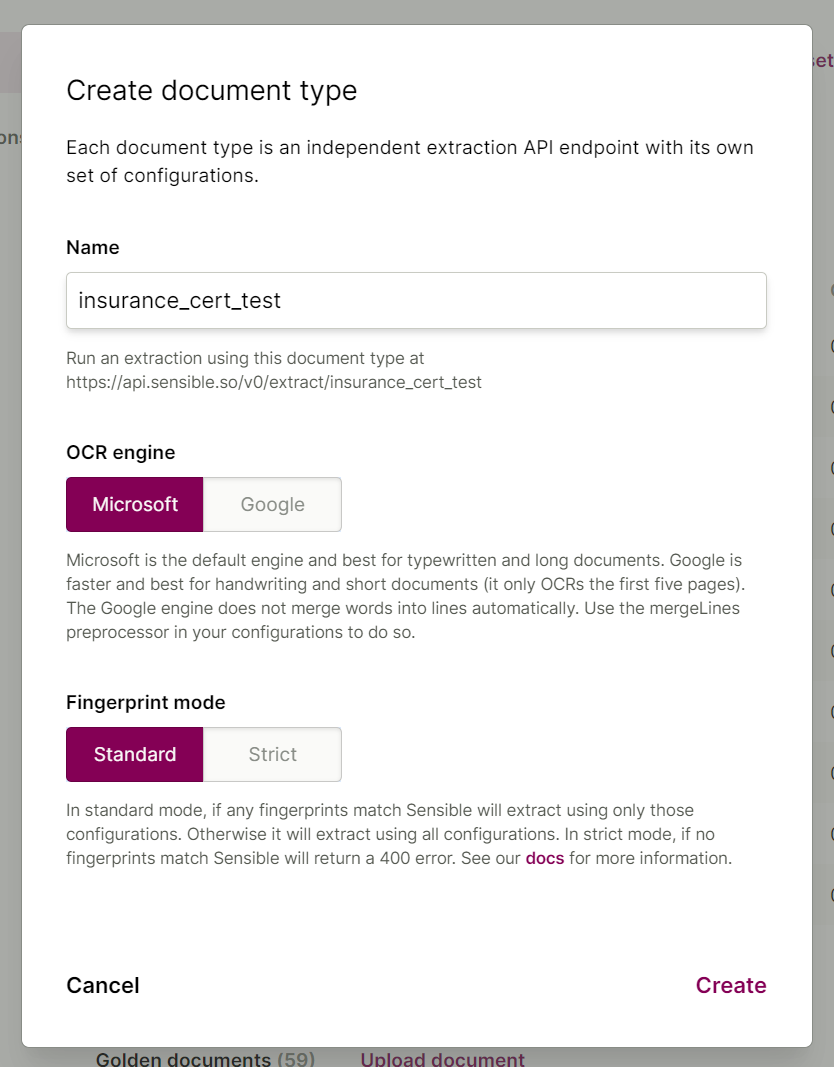
2. Click Create document type and name it "insurance_cert_test". Leave the defaults and click Create.
3. Click Upload document and choose the certificate of insurance you already downloaded.
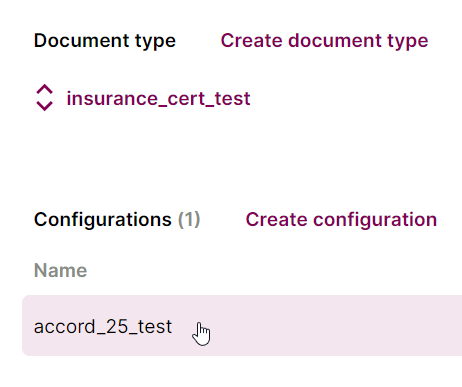
4. Click Create configuration, name it "acord_25_test" (for the form number), and click Create.
5. Click the configuration name to edit the configuration:
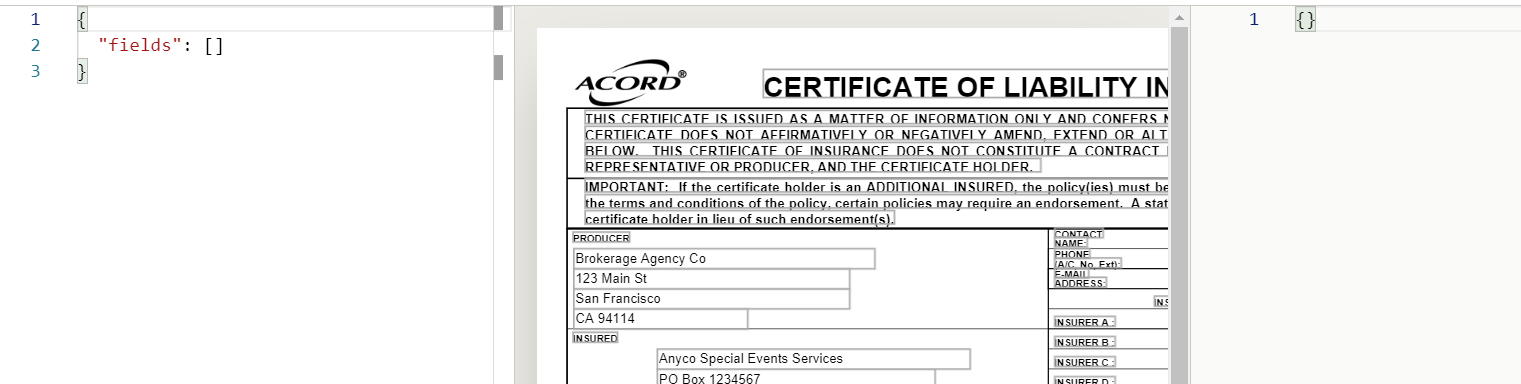
When the configuration opens, you see an empty config pane on the left, the PDF in the middle, and an empty output pane on the right:
Let's start extracting data!
Extract the certificate number
To grab the certificate number:

Add the following query, or "field" into the right pane of the Sensible app:
You should see the following extracted data in the right pane:
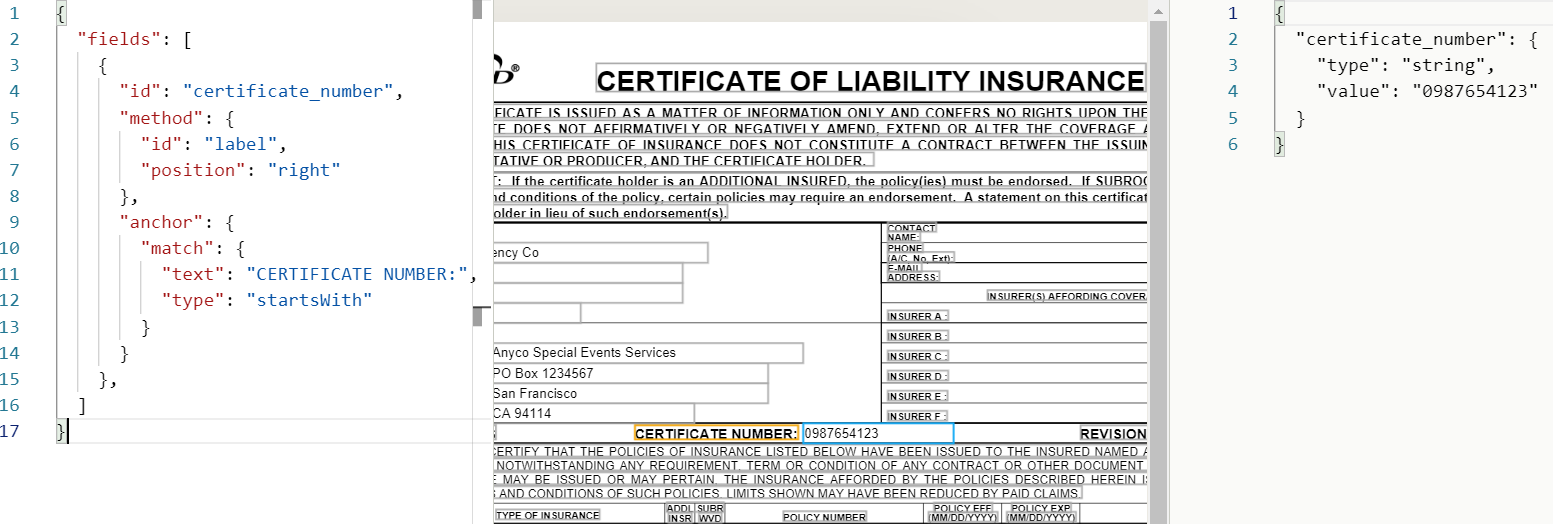
What’s going on here?
- The query first anchors on some text ("anchor": {}), because it's a quick way to narrow down where to grab data in the document.
- The query then uses a method ("method":{}) to expand out from the anchor and grab the data you want.
- The query uses the Label method ("id": "label") to extract the data. This tells Sensible that the anchor text ("CERTIFIATE NUMBER") is positioned closely to the text you want to grab.
- The query should grab the text to the right of the label ("position": "right").
Extract occurrence limit
To grab the general liability occurrence dollar limit ($2 million), we can’t anchor on "EACH OCCUENCE" as a label. The Label method only work for closely proximate lines, and these lines are separated by large gaps (line boundaries are shown as gray boxes):

Let's instead use the purpose-built Row method to grab the occurrence dollar limit. Paste the following query into the right pane of the Sensible app:
You should see the dollar amount extracted in the right pane:

This query tells Sensible that:
- The anchor text ("each occurrence") is aligned on a horizontal line with the target data in a row-like arrangement ("id": "row").
- Sensible should only return a row element whose value is a currency ("type": "currency").
- It’s not shown, but by default, the Row method grabs data to the right of the anchor ("position": "right").
Extract professional liability expiration date
To expand a little on the Row method, let’s extract the expiration date for professional liability (02/12/2021):

Add the following query to the left pane of the Sensible app:
You should see the following output:
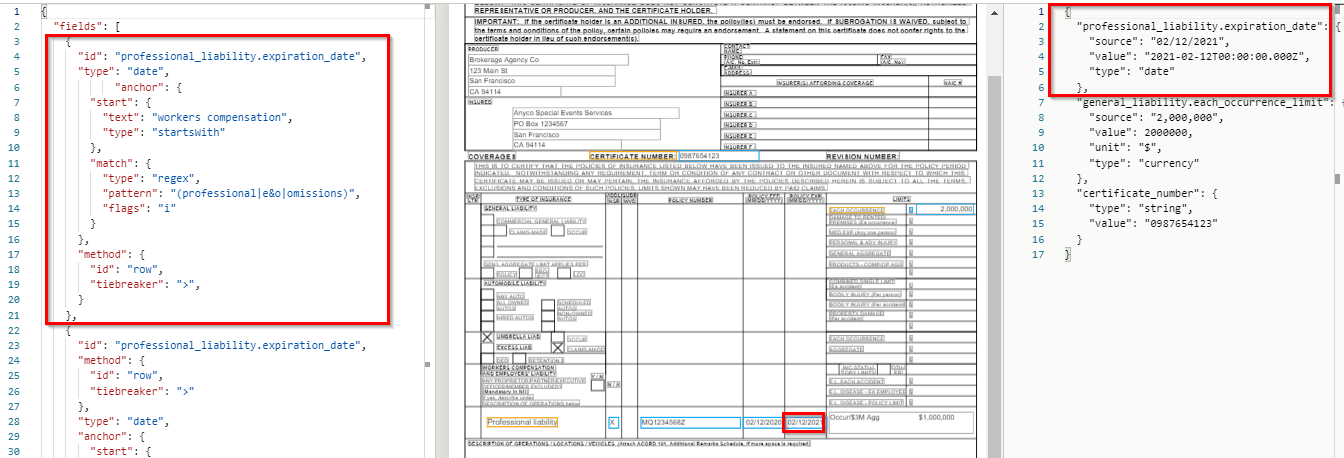
Up to this point, we’ve looked at anchors that simply match on a string. This query’s anchor is more complex:
- The anchor matches on synonymous terms using a regular expression ("(professional|e&o|omissions)"). Since different brokers can enter these terms interchangeably in freeform input areas, we search for all synonyms.
- These terms can occur earlier in the document, but we want the later occurrence. So we start searching for the anchor match only after a line that includes the text "workers compensation" ("start": {"text": "workers compensation", "type": "includes"}).
This query also shows that we can use a tiebreaker to choose a row element. In this case we choose the larger ("tiebreaker": ">") of two dates ("type": "date").
Extract broker
To grab the broker who produced the certificate:

Add the following query into the left pane in the Sensible app:
You should see the following output:

This query grabs all the lines inside a box as a single string. It recognizes the box by looking for dark pixels signifying borders, expanding out from the right edge of the anchor line's boundaries ("position": "right").
Extract claims made
To extract whether the umbrella liability claims-made checkbox is checked or not:

Paste the following query to your config into the left pane of the Sensible app:
You should see in the Sensible output that the checkbox’s value is "true" (i.e., checked):
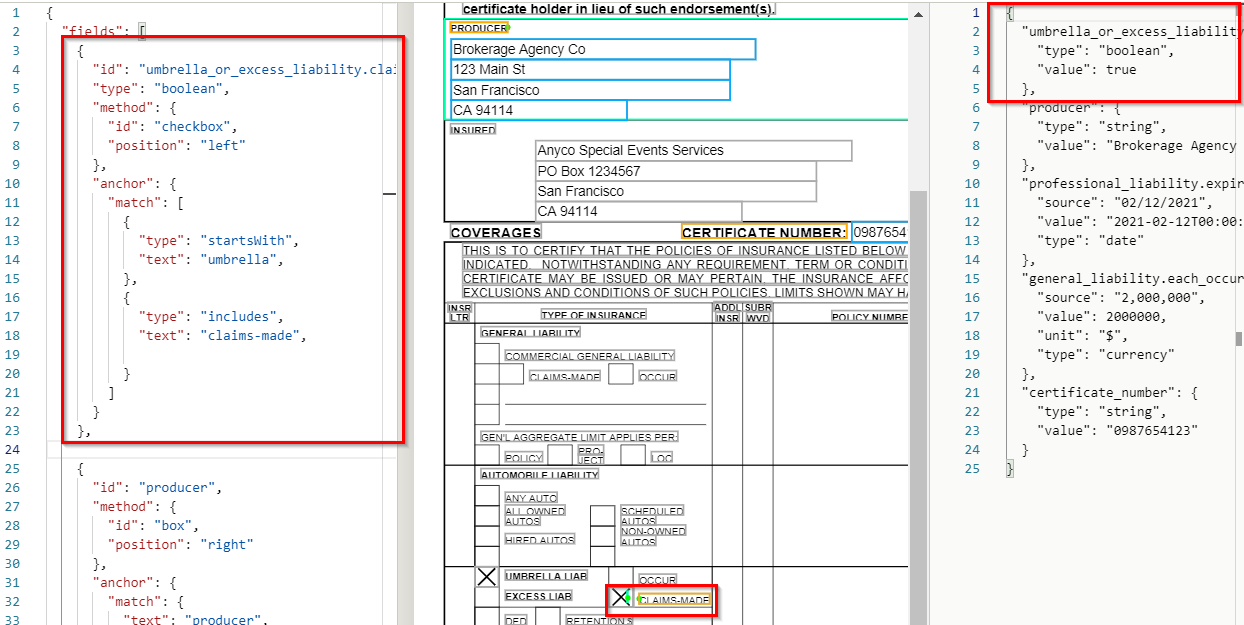
This query searches for a checkbox to the left of the anchor ("position": "left"). The multi-part anchor only matches the text "claims-made" if it's preceded by the text "umbrella." This rules out false matches on other "claims-made" checkboxes, such as the one in the general liability section.
Dealing with document variations
How do you find reliable anchors if different form revisions use different terms? That turns out to be a challenge in the preceding "claims made" query. The 20106/03 version of this form breaks the query, because it only includes the text "excess liability", not "umbrella":
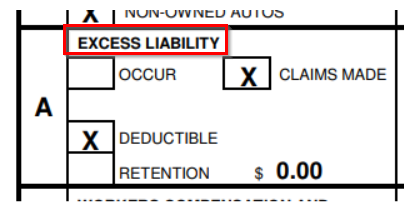
So, let’s change this query to use regular expressions to search for:
- either "UMBRELLA" or "EXCESS LIAB"
- either "claims-made" or "claims made"
Replace your previous "claims made" query with the following:
And it will work with various form revisions.
Another approach to capturing variable form data is to use a fallback query. If you define two queries with the same ID, then Sensible falls back to the second if the first returns null. So, instead of regular expressions, we could split the previous query into two queries, like this:
These two fields capture data from both the 2010/05 and 2016/03 variants of the ACORD 25 document.
Get extracting!
Congratulations, you’ve learned about some key methods for extracting structured data from PDF documents. There’s lots more to cover in another post, including extracting image coordinates, preprocessing to clean up oddly formatted PDFs, OCR strategies for handwritten text, and optimizing extraction performance. Check out our docs, and sign up for Sensible trial to start extracting data from your own documents.



.png)