

A previous tutorial covered extracting structured data from documents using SenseML. Let's switch gears to optimizing your data extraction.
What we'll cover
- What impacts Sensible performance?
- Rewrite SenseML queries for faster performance
- Preferentially run or skip collections of queries ("configs") based on key text in documents.
What impacts Sensible performance?
First, let's clarify what doesn't impact performance: the number of documents you submit has virtually no effect on processing time. Each document gets its own worker in parallel, whether you submit one or 50,000 documents. Instead, you can optimize:
- document performance
- document type performance
Document performance
In an ideal performance scenario, you extract data from digitally generated PDFs using only text-based or coordinate-based SenseML methods, such as Label, Row, Region, Text Table, and Document Range.
In the real world, things are never that simple. In order of slowest to quickest, these factors add seconds to doc processing:
Over 10 seconds per document
Whole-document OCR (for scanned documents)
Sensible takes 10 seconds or more to OCR an entire document. You can speed OCR up for shorter documents (5 pages or fewer) by choosing Sensible's Google OCR option.
Whole-document table recognition
Avoid configuring Sensible to search a whole document for tables. For a tutorial, see the "Add a Stop" section in this post.
Under 5 seconds per document
Selective OCR
Some documents mix digital text with text images, for example by embedding scanned pages in a digital PDF. Speed this up by OCRing select pages, not the whole document. For more information, see the docs.
Selective table recognition
Sensible process tables that include a stop in less than 5 seconds. Or, convert to a faster method that skips table recognition. For a tutorial, see "Add a Stop" and "Convert to faster query" sections in this post.
Under 1 second per document
Some SenseML methods use pixels, for example to recognize borders. However, pixel recognition requires rendering a PDF page, which can take a couple hundred milliseconds. To improve processing time, use coordinate-based alternatives to these methods.
Boxes
To improve processing speed, convert the more flexible Box method to the strictly coordinate-based Region method.
Signature, checkbox, image coordinate extraction
There are no alternative methods for signatures, checkboxes, and images. However, see the following section for ways to avoid running these methods except when absolutely necessary.
Document type performance
By default, Sensible runs all the configs in a document type before choosing the best one for a given document. If your document type contains many different configs with computationally expensive methods such as Table or Box, you can improve performance by selectively running and skipping configs. For a tutorial, see the Skip queries section later in this post.
Enough overview! Let's dive into some real-world optimizing.
Prerequisites
- You’ll need an account for Sensible. Or, read along for a rough idea of how things work.
- Upload the Example commercial insurance application to the Sensible app in a document type named "acord_application_test". If you're unfamiliar with the Sensible app, follow the steps in create a document type and config. Then, paste the following SenseML into an "acord_125_test config" in the Sensible app to extract the data:
You should see that Sensible recognizes the table (green box):

And you should see the following data extracted from the "loss history" table in the output pane:
Optimize query speed
The Fixed Table method in the preceding example is convenient when the table column layout never varies. But for long documents, the defaults for Fixed Table can result in slower performance. So let's optimize it!
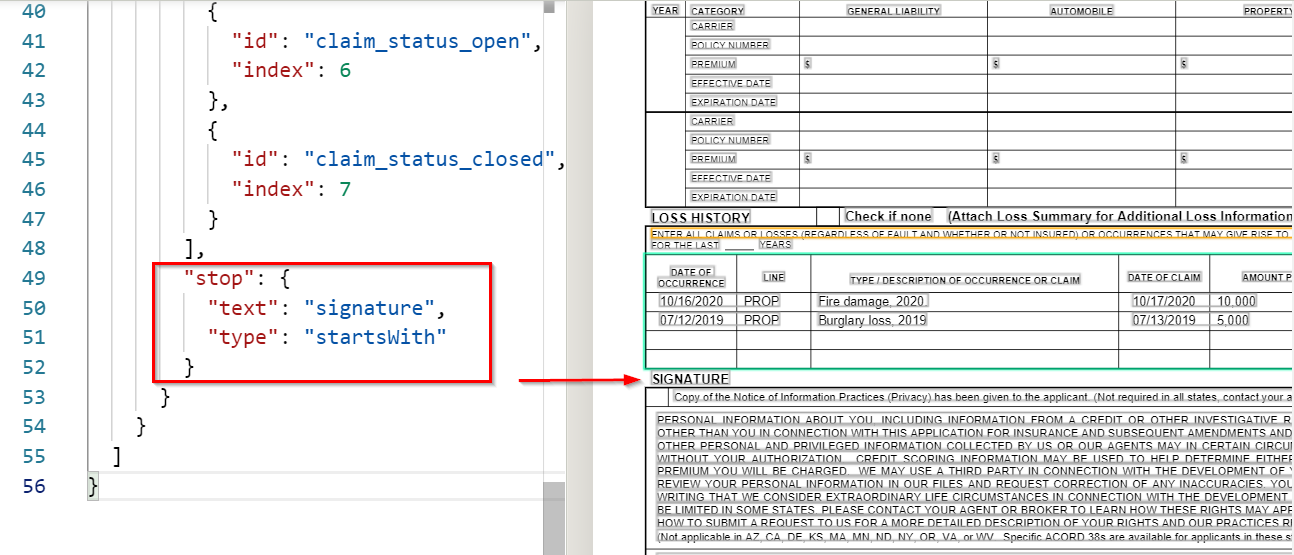
Best practice: table stops
If you don't define the end of the table, Sensible runs table recognition on all the pages in the document. This impacts performance for long documents.
To define the table stop, append the following Stop parameter after your column array:
This specifies to stop table recognition as soon as Sensible encounters a line that starts with the text "signature":
Convert to a faster query
For faster extraction, skip table recognition by replacing the Fixed Table method with the Text Table method.
Replace your "acord_125_test" config with the following SenseML:
As the preceding code sample shows, the Text Table method defines columns using coordinates. To determine these coordinates, click the table heading the Sensible app to display the heading line coordinates.
This code sample also uses a Split Lines preprocessor; otherwise the strict Text Table method stumbles on a couple of overmerged lines in the table.
Selectively skip queries
Imagine you process more than one type of application under an "acord_application_test" document type. For example, you process:
- ACORD 125 - Commercial Insurance Application
- ACORD 130 - Workers Compensation Application
In this situation, Sensible automatically chooses the best config for each document, so you don't have to specify "acord_125" or "acord_130" in your API calls. Behind the scenes, Sensible runs all the configs in the "acord_application_test" document type and chooses the output with the highest percentage of non-null values.
But what if you don't want Sensible to run all the configs? It might slow you down, especially if your configs contain computationally expensive methods like Table and Box.
In that case, you add a fingerprint to a config before the Fields array. A fingerprint tests whether a document contains matching text before skipping or running a config. For example, you can test that a document is an ACORD 125 with the following fingerprint:
With this fingerprint, Sensible preferentially:
- runs the "acord_125_test" config on a document if it finds at least 50% of the strings defined in the fingerprint tests
- skips configs with no fingerprint
Get optimizing!
Congratulations, you've learned about some key methods for optimizing your PDF extractions. Check out our docs, and sign up for Sensible trial to start extracting from your own documents.
.png)
.webp)

